Behaviour of Ouroboros flows vs UDP sockets and TCP connections/sockets
A couple of days ago, I received a very good question from someone who was playing around around with Ouroboros/O7s. He started from the oecho tool.
oecho is a very simple application. It establishes what we call a “raw” flow. Raw flows have no fancy features, they are the best-effort class of packet transport (a bit like UDP). Raw flows do not have an Flow-and-retransmission control protocol (FRCP) machine. This person changed oecho to use a reliable flow, and slightly modified it, ran into some unexpected behaviour,and then asked: is it possible to detect a half-closed connection? Yes, it is, but it’s not implemented (yet). But I think it’s worth answering this in a fair bit of detail, as it highlights some differences between O7s flows and (TCP) connections.
A bit of knowledge on the core protocols in Ouroboros is needed, and can be found here and the flow allocator here. If you haven’t read these in while, it will be useful to first read them to make the most out of this post.
The oecho application
The oecho server is waiting for a client to request a flow, reads the message from the client, sends it back, and deallocates the flow.
The client will allocate a raw flow, the QoS parameter for the flow is NULL. Then it will write a message, read the response and also deallocate the flow.
In a schematic, the communication for this simple application looks like this1:
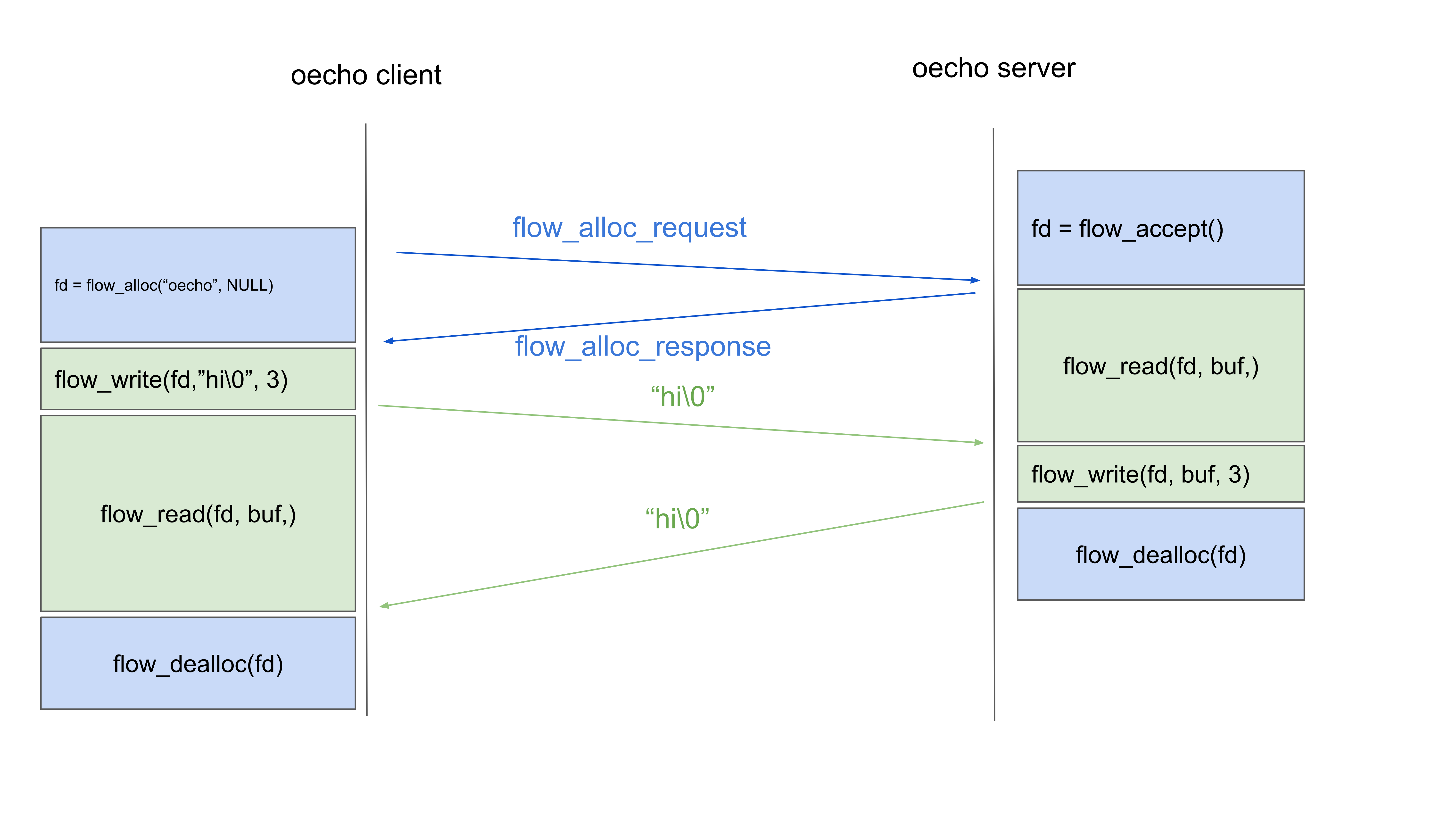
All the API calls used are inherently blocking calls. They wait for some event to happen and do not always return immediately.
First, the client will allocate a flow to the server. The server’s flow_accept() call will return when it receives the request, the client’s flow_alloc() call will return when the response message is received from the server. This exchange agrees on the Endpoint IDs and possibly the flow characteristics (QoS) that the application will use. For a raw flow, this will only set the Endpoint IDs that will be used in the DT protocol2. On the server side, the flow_accept() returns, and the server calls flow_read(). While the flow_read() is still waiting on the server side, the flow allocation response is underway to the client. The reception of the allocation response causes the flow_alloc() call on the client side to return and the (raw) flow is established3.
Now the client writes a packet, the server reads it and sends it back. Immediately after sending that packet, the server deallocates the flow. The response, containing a copy of the client message, is still on its way to the client. After the client receives it, it also deallocates the flow. Flow deallocation destroys the state associated with the flow and will release the EIDs for reuse. In this case of raw, unreliable flows, flow_dealloc() will return almost immediately.
Flows vs connections
The most important thing to notice from the diagram for oecho, is that flow deallocation does not send any messages! It only cleans up local state. Suppose that the server would send a message to destroy the flow immediately after it sends the response. What if that message to destroy the flow arrives before the response? When do we destroy the state associated with the flow? Flows are not connections. Raw flows like the one used in oecho behave like UDP. No guarantees. Now, let’s have a look at reliable flows, which behave more like TCP.
A modification to oecho with reliable flows
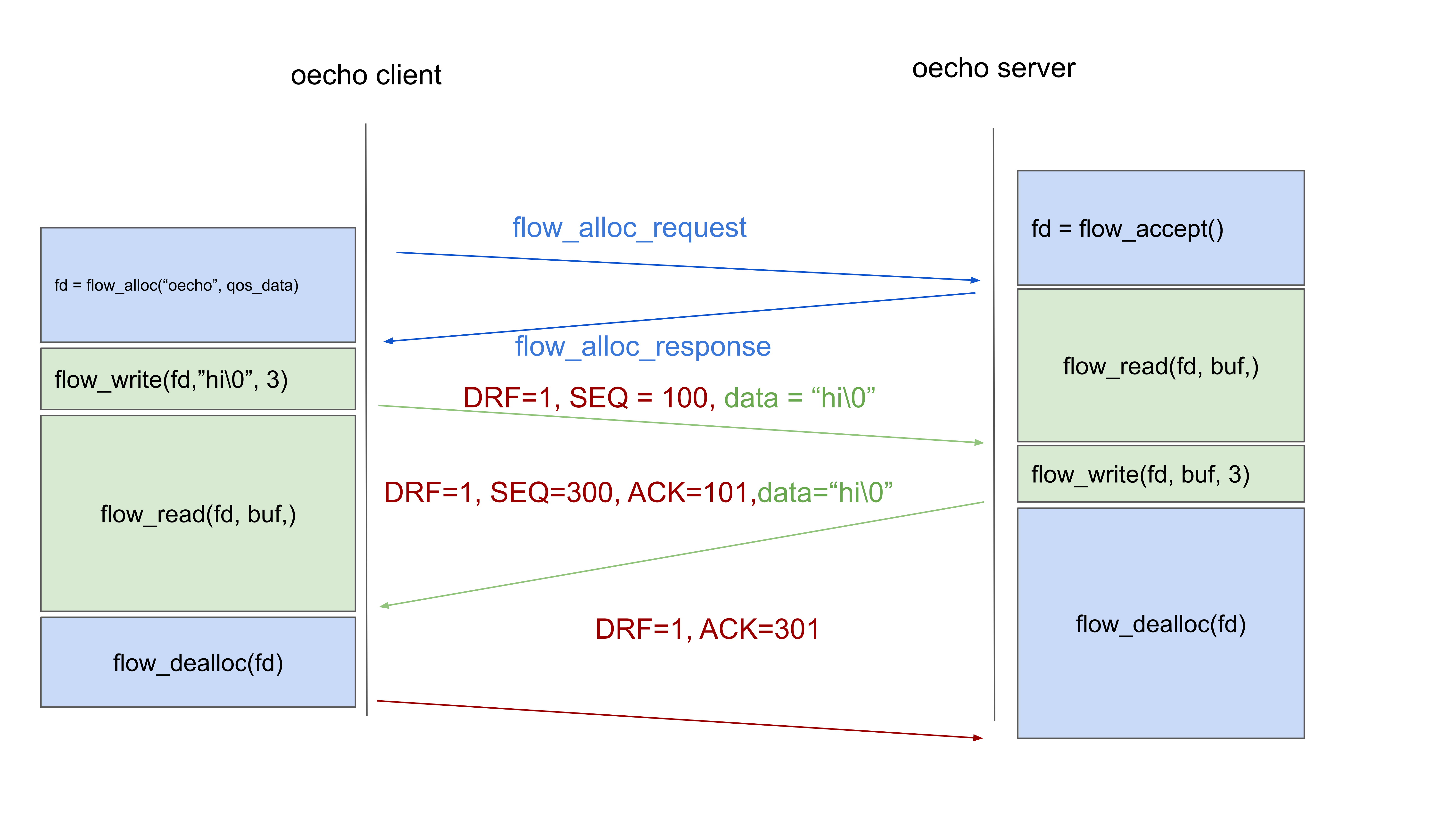
To use a reliable flow, we call a flow_alloc() from the client with a different QoS spec (qos_data). The flow allocation works exactly as before. The flow allocation request now contains a data QoS request instead of a raw QoS request. Upon reception of this request, the server will create a protocol machine for FRCP, the protocol in O7s that is in charge of delivering packets reliably, in-order and without duplicates. FRCP also performs flow control to avoid sending more packets than the server can process. When the flow allocation arrives at the client, it will also create an FRCP protocol instance. When these FRCP instances are created, they are in an initial state where the Delta-t timers are timed out. This is the state that allows starting a new run. I will not explain every detail of FRCP here, these are explained in the protocols section.
Now, the client sends its first packet, with a randomly chosen sequence number (100) and the Data Run Flag (DRF) enabled. The meaning of the DRF is that there were no previously unacknowledged packets in the currently tracked packet sequence, and it allows to avoid a 3-way handshake.
When that packet with sequence number 100 arrives in the FRCP protocol machine at the server, it will detect that DRF is set to 1, and that it is in an initial state where all timers are timed out. It will start accepting packets for this new run starting with sequence number 100. The server almost immediately sends a response packet back. It has no active sending run, so a random sequence number is chosen (300) and the DRF is set to 1. This packet will contain an acknowledgment for the received packet. FRCP acknowledgements contain the lowest acceptable packet number (so 101). After sending the packet, the server calls dealloc(), which will block on FRCP still having unacknowledged packets.
Now the client gets the return packet, it has no active incoming run, the receiver connection is set to initial timed out state, and like the server, it will see that the DRF is set to 1, and accept this new incoming run starting from sequence number 300. The client has no data packets anymore, so the deallocation will send a bare acknowledgement for 301 and exit. At the server side, the flow_dealloc() call will exit after it receives the acknowledgement. Not drawn in the figure, is that the flow identifiers (EIDs) will only time out internally after a full Delta-t timeout. TCP does something similar and will not reused closed connection state for 2 * Maximum Segment Lifetime (MSL).
Unexpected behaviour
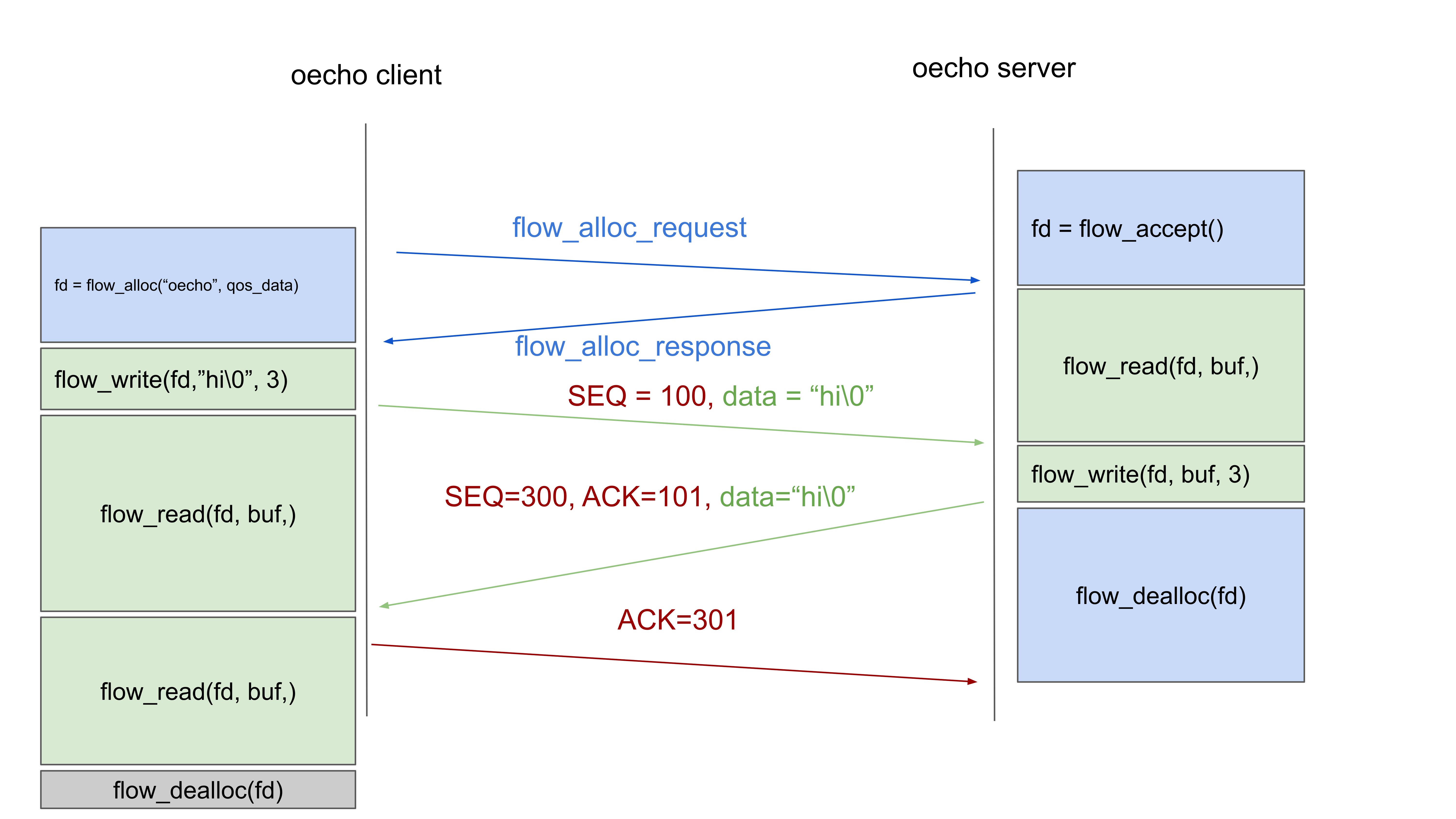
While playing around with the prototype, a modification was made to oecho as above: another _flowread() was added to the client. As you can see from the diagram, there will never be a packet sent, and, if no timeout is set on the read() operation, after the server has deallocated the flow (and re-entered the loop to accept a new flow), the client will remain in limbo, forever stuck on the flow_read(). And so, I got the following question:
I would have expected the second call to abort with an error
code. However, the client gets stuck while the server is waiting for a
new request. Is this expected? If so, is it possible to detect a
half-closed connection?
A “half-closed connection”
So, first things first: the observation is correct, and that second call should (and soon will) exit on an error, as the flow is not valid anymore. Now it will only exit if there was an error in the FRCP connection (packet retransmission fails to receive an acknowledgment within a certain timeout). It should also exit on a remotely deallocated flow. But how will Ouroboros detect it?
Now, a “half closed connection” comes from TCP. TCP afficionados will probably think that I need to add something to FRCP, like FIN at the end of TCP to signal the end of a flow4:
TCP A TCP B
1. ESTABLISHED ESTABLISHED
2. (Close)
FIN-WAIT-1 --> <SEQ=100><ACK=300><CTL=FIN,ACK> --> CLOSE-WAIT
3. FIN-WAIT-2 <-- <SEQ=300><ACK=101><CTL=ACK> <-- CLOSE-WAIT
4. (Close)
TIME-WAIT <-- <SEQ=300><ACK=101><CTL=FIN,ACK> <-- LAST-ACK
5. TIME-WAIT --> <SEQ=101><ACK=301><CTL=ACK> --< CLOSED
6. (2 MSL) CLOSED
While FRCP performs functions that are present in TCP, not everything is so readily transferable. Purely from a design perspective, it’s just not FRCP’s job to keep a flow alive or detect if the flow is alive. It’s job is to deliver packets reliably, and all it needs to do that job is present. But would adding FINs work?
Well, the server can crash just before the dealloc() call, leaving it in the current situation (the client won’t receive FINs). To resolve it, it would also need a keepalive mechanism. Yes, TCP also has a keepalive mechanism. And would adding that solve it? Not to my satisfaction. Because, Ouroboros flows are not connections, they don’t always have an end-to-end protocol (FRCP) running5. So if we add FIN and keepalive to FRCP, we would still need to add something similar for flows that don’t have FRCP. We would need to duplicate the keepalive functionality somewhere else. The main objective of O7s is to avoid functional duplication. So, can we kill all the birds with one stone? Detect flows that are down? Sure we can!
Flow liveness monitoring
But we need to take a birds eye view of the flow first.
On the server side, the allocated flow has a flow endpoint with internal Flow ID (FID 16), to which the oecho server writes using its flow descriptor, fd=71. On the client side, the client reads/writes from its fd=68, which behind the scenes is linking to the flow endpoint with ID 9. On the network side, the flow allocator in the IPCPs also reads and writes from these endpoints to transfer packets along the network. So, the flow endpoint marks the boundary between the “network”.
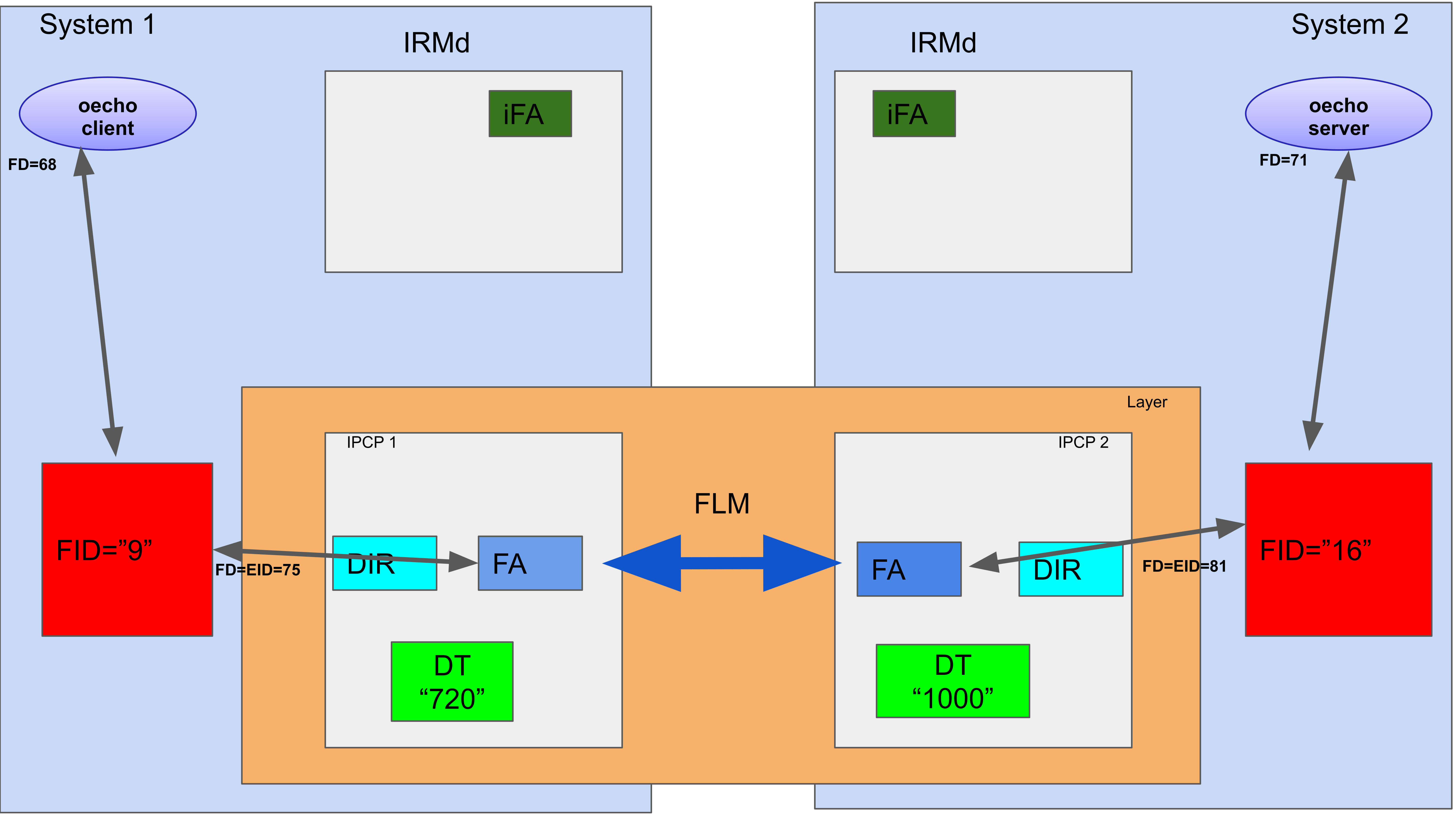
This is drawn in the figure above. I’ll repeat it because it is important: the datastructure associated with a flow at the endpoints is this “flow endpoint”. It forms the bridge between the application and the network layer. The role of the IRMd is to manage these endpoints and the associated datastructures.
Flow deallocation is a two step process: both the IPCP and the application have a dealloc() call. The endpoint is only destroyed if both the application process and the IPCP signal they are done with it. So a flow_dealloc() from the application will kill only its use with the endpoint. This allows the IRMd to keep it alive until it sends an OK to the IPCP to also deallocate the flow and signal it is done with it. Usually, if all goes well, the application will deallocate the flow first.
The IRMd also monitors all O7s processes. If it detects an application crashing, or an IPCP crashing, it will automatically perform that applications’ half of the flow deallocation, but not the complete deallocation. If an IPCP crashes, applications still hold the FRCP state and can recover the connection over a different flow6.
Edit: the below section is not correct, but it’s interesting to read anyway7. There is a new post, documenting the actual implementation.
So, now it should be clear that the liveness of a flow has to be detected in the flow allocator of the IPCPs, not in the application (again, reminder: FRCP state is maintained inside the application). The IPCP will detect that its flow has been deallocated locally (either intentionally or because of a crash).It’s paramount to do it here, because of the recursive nature of the network. Flows are everywhere, also between “router machines”! Routers usually restrict themselves to raw flows. No retransmissions, no flow control, no fuss, that’s all too expensive to perform at high rates. But they need to be able to detect links going down. In IP networks, the OSPF protocol may use something like Bi-directional Forwarding Detection (BFD) to detect failed adjacencies. And then applications may use TCP keepalive and FIN. Or HTTP keepalive. All unneeded functional duplication, symptoms of a messy architecture, at least in my book. In Ouroboros, this flow liveness check is implemented once, in the flow allocator. It is the only place in the Ouroboros system where liveness checks are needed. It handles failed allocation, broken connections, terminated or crashed applications. Clean. Shipshape. Nice and tidy. Spick and span. We call it Flow Liveness Monitoring (FLM).
If I recall correctly, we implemented an FLM in the RINA/IRATI flow allocator years ago when we were working on PRISTINE and were trying to get loop-free alternate (LFA) routes working. This needed to detect flows going down. In Ouroboros it is not implemented yet. Maybe I’ll add it in the near future. Time is in short supply, the items on my todo list are not.
Flows vs connections, a “layered” view
To wrap it up, I tried to represent how O7s functionality is organized in a way similar to the OSI/TCP models. I omitted the “physical layer”, which is handled by dedicated IPCP implementations, such as the ipcpd-local, ipcpd-eth, etc. It’s not that important here. What is important is that O7s splits functionality that is in TCP/IP in two layers (L3/L4), into 3 independent layers0. Let’s go through O7s from bottom to top.
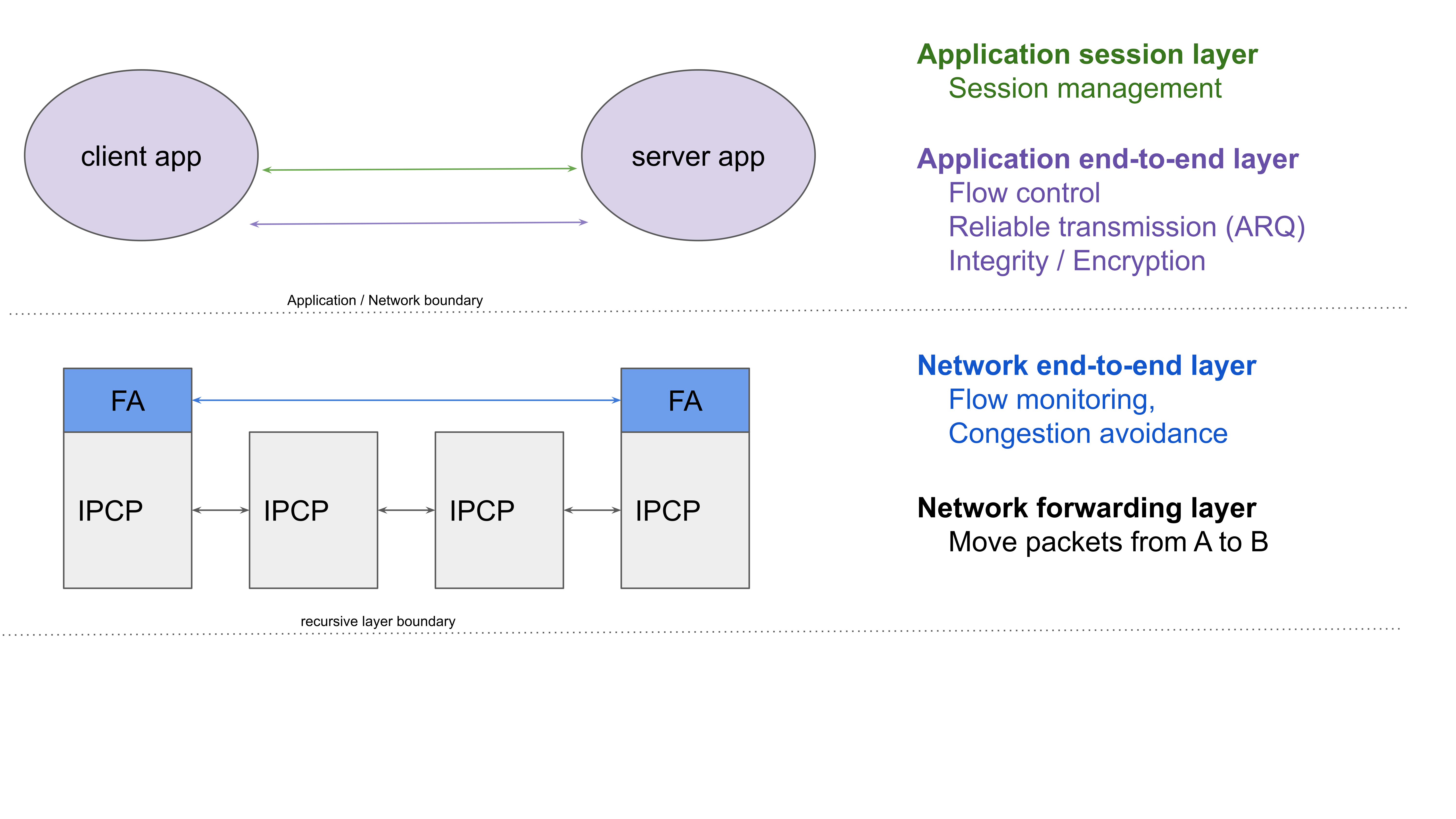
Network forwarding layer, which moves packets between (unicast) IPCP data transfer components (the forwarding elements in the model).
The network end-to-end layer does flow monitoring (the FLM explained in this post) and also congestion control/avoidance (preventing that applications can send more traffic than the network can handle). The lifetime of a flow starts at flow allocation, and ends when one of the peers deallocates the flow, or crashes, (or an IPCP at the client or server crashes).
The application end-to-end layer does flow control (avoiding that client applications send more than the server application can handle) and reliability (taken care of by FRCP). But also integrity (e.g. a Cyclic Redundancy Check) to detect packet corruption and authentication and encryption are handled here. Each of these functions can be enabled/disabled indepenendently (and is derived from the QoS specification from the flow_alloc() call). In essence the lifetime of an FRCP connection is infinite (see Watson’s Delta-t paper if this sounds weird), but FRCP is subdivided in “data runs”. A failure of a data run (i.e. an FRCP connection record times out with unacknowledged packets) is the only thing that causes an FRCP connection to terminate. It is up to the application how to deal with this. An FRCP connection can last at most as long as an application flow. It can potentially recover from IPCP crashes, but not from application crashes.
Finally, the application session layer takes care of establishing, maintaining, synchronizing and terminating application sessions. Application sessions can be shorter, as long as, or longer than the duration of an application flow.
Probably long enough for a blog post. Have yourselves a wonderful new year, and above all, stay curious!
Dimitri
We are omiting the role of the Ouroboros daemons (IPCPd’s and IRMd) for now. There would be a name resolution step for “oecho” to an address in the IPCPds. Also, the IRMd at the server side brokers the flow allocation request to a valid oecho server. If the server is not running when the flow allocation request arrives at the IRMd, O7s can also start the oecho server application in response to a flow allocation request. But going into those details are not needed for this discussion. We focus solely on the application perspective here.
[return]Flow allocation has no direct analogue in TCP or UDP, where the protocol to be used and the destination port are known in advance. In any case, flow allocation should not be confused with a TCP 3-way handshake.
[return]I will probably do another post on how flow allocation deals with lost messages, as it is also an interesting subject.
[return]- Or even more bluntly tell me to “just use TCP instead of FRCP”. [return]
A UDP server that has clients exit or crash is also left to its own devices to clean up the state associated with that UDP socket.
[return]This has not been implemented yet, and should make for a nice demo.
[return]After implementing the solution below, it became apparent to me that something was off. I needed to leak the FRCP timeout into the IPCP, which is a layer violation. I noted this fact in my commit message, but after more thought, I decided to retract my patch… it just couldn’t be right. This layer violation didn’t come up when we implemented FLM in the Flow allocator RINA, because RINA puts the whole retransmission logic (called DTCP) in the IPCP.
[return]