What is wrong with the architecture of the Internet?
There are two ways of constructing a software design: One way is to
make it so simple that there are obviously no deficiencies, and the
other way is to make it so complicated that there are no obvious
deficiencies. The first method is far more difficult. -- Tony Hoare
Introduction
There are two important design principles in computer science that are absolutely imperative in keeping the architectural complexity of any technological solution (not just computer programs) in check: separation of concerns and separation of mechanism and policy.
There is no simple 2-line definition of these principles, but here’s how I think about them. Separation of concerns allows one to break down a complex solution into different subparts that can be implemented independently and in parallel and then integrated into the completed solution. Separation of mechanism and policy, when applied to software abstractions, allows the same subpart to be implemented many times in parallel, with each implementation applying different solutions to the problem.
Both these design principles require the architect to create abstractions and define interfaces, but the emphasis differs a bit. With separation of concerns, the interfaces define an interaction between different components, while with separation of mechanism and policy, the interfaces define an interaction towards different implementations, basically separating the what the implementation should do from the how the implementation does it. An interface that fully embraces one of these principles, usually embraces the other.
One of the best known examples of separation of concerns is the model-view-controller design pattern:
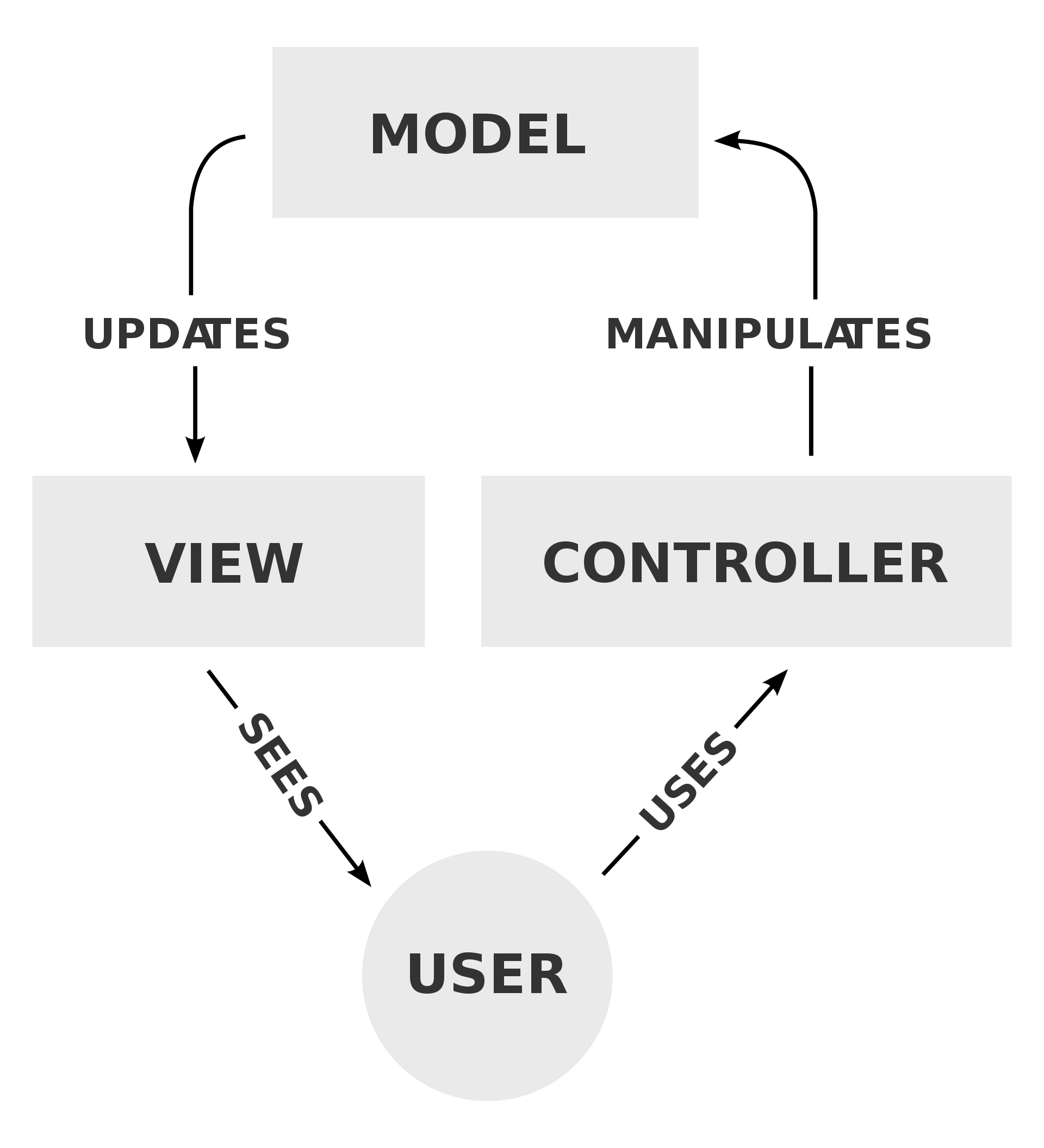
The model is concerned with the maintaining the state of the application, the view is concerned with presenting the state of the application, and the controller is concerned with manipulating the state of the application. The keywords associated with good separation of concerns are modularity and information hiding. The view doesn’t need to know the rules for manipulating the model, and the controller doesn’t need to know how to present the model.
As very simple example for separation of mechanism and policy is the mechanism sort - returning a list of elements in some order - which can be implemented by different policies quick-sort, bubble-sort or insertion-sort. But that’s not all there’s to it. The key is to hide the policy details from the interface into the mechanism. For sort this is simple, for instance, sort(list, order=‘descending’) would be an obvious API for a sort mechanism. But it goes much further than that. Good separation of mechanism and policy requires abstracting every aspect of the solution behind an implementation-agnostic interface. That is far from obvious.
Trade-offs
Violations of these design principles can cause a world of hurt. In most cases, they do not cause problems with functionality. Even bad designs can be made to work. They cause development friction and resistance to large-scale changes in the solution. Separation of concerns violations make the application less maintainable because changes to some part cascade into other parts, causing spaghetti code. Violation of separation of mechanism and policy make an application less nimble because some choices get anchored in the solution, for instance the choice for a certain encryption library or a certain database solution and directly calling these proprietary APIs from all parts of the application. This tightly locked in dependency can cause serious problems if these dependencies cease to be available (deprecation) or show serious defects.
Good design lets development velocities add up. Bad design choices slow development because progress that should be independent starts to interlock. Ever tried running with your shoelaces knotted to someone else’s? Whenever one makes a step forward, the other has to catch up.
Often, violations against these 2 principles are made in the name of optimization. Let’s have a quick look at the trade-offs.
Separation of concerns can have a performance impact, so a choice has to be made between the current performance, and future development velocity. In most cases, code that violates separation of concerns is harder to adapt and (much) harder to thoroughly test. My recommendation for developers is to approach such situations by first creating the API and implementation respecting separation of concerns and then after very careful consideration, create a separate additional low-level optimized API with an optimized implementation. Then the optimized implementation can be tested (and performance-evaluated) against the functionality (and performance) of the non-optimized one. If later on, functionality needs to be added to the implementation, having the non-optimized path will prove a timesaver.
Separation of mechanism and policy usually has less of a direct performance impact, and the tradeoff is commonly future development velocity versus current development time. So if this principle is not respected by choice, the driver for it is usually time pressure. If only a single implementation is used what is the point of abstracting the mechanism behind an API? More often than not, though, violations against mechanism/policy just creep in unnoticed. The negative implications are usually only felt a long way down the line.
But we haven’t even gotten to the hardest part yet. A well-known phrase is that there are 2 hard things in computer science: cache invalidation and naming things (and off-by-one errors). I think it misses one: identifying concerns. Or in other words: finding the right abstraction. How do we know when an abstraction is the right one? Designs with obvious defects will usually be discarded quickly, but most design glitches are not obvious. There is a reason that Don Knuth named his tome “The Art of Computer Programming”. How can we compare abstractions, can we quantify elegance or is it just taste? How much of the complexity of a solution is inherent in the problem, and how much complication is added because of imperfect abstraction? I don’t have an answer to this one.
A commonly used term in software engineering for all these problems is technical debt. Technical debt is to software as entropy is to the Universe. It’s safe to state that in any large project, technical debt is inevitable and will only accumulate. Fixing technical debt requires investing a lot of time and effort and usually brings little immediate return on this investment. The first engineering manager that happily invests time and money towards refactoring has yet to be born.
Layer violations in the TCP/IP architecture
Now what have this software development principles to do with the architecture of the TCP/IP Internet1?
I find it funny that the wikipedia page uses the Internet’s layered architecture as an example for separation of concerns because I use it as an example of violations against it. The intent is surely there, but the execution is completely lacking.
Let’s take some examples the common TCP/IP/Ethernet stack violates the 2 precious design principles. In a layered architecture (like computer network architectures), they are called layer violations.
Layer 1: At the physical layer, Ethernet has a minimum frame size, which is required to accurately detect collisions. For 10/100Mbit this is 64 bytes. Shorter frames must be padded. How to distinguish the padding from a packet which actually has zeros at the end of its data? Well, Ethernet has a length field in the MAC header. But in DIX Ethernet that is an Ethertype, so a length field in the IP header is used (both IPv4 as IPv6). A Layer 1 problem is actually propagated into Layer 2 and even Layer 3. Gigabit Ethernet has an even larger minimum frame sizes (512 bytes), however, the padding is properly (and efficiently!) taken care of at Layer 1 by a feature called Carrier Extension.
Layer 2: The Ethernet II frame has an Ethertype, which is also a layer violation, specifying the encapsulated higher-layer protocol. 0x800 for IPv4, 0x86DD for IPv6, 0x8100 for tagged VLANs, etc.
Layer 3: Similarly as the Ethertype, IP has a protocol field, specifying the carried protocol. UDP = 17, TCP = 6. Other tight couplings between Layer 2 and Layer 3 are, IGMP snooping and even basic routing2. One thing worth noting, and often disregarded in course materials on computer networks, is that OSI’s 7 layers each had a service definition that abstracts the function of each layer away from the other layers so these layers can be developed independently. TCP/IP’s implementation was mapped to the OSI layers, usually compressed to 5-layers, but TCP/IP has no such service definitions. The interfaces into Layer 2 and Layer 3 basically are the protocol definitions. Craft a valid packet according to the rules and send it along.
Layer 4: My favorite. Well-known ports. HTTP: TCP port 80, HTTPs: TCP port 443, UDP port 443 is now predominantly QUIC/HTTP3 traffic. This of course creates a direct dependency between application protocols and the network.
Explaining these layer violations to a TCP/IP network engineer is like explaining inconsistencies and contradictions in the bible to a priest. So why do I care so much, and a lot of IT professionals brush this off as nitpicking? Let’s first look at what I think are the consequences of these seemingly insignificant pet peeves of mine.
Network Ossification
The term ossification of the Internet is sometimes used to describe difficulties in making sizeable changes within the TCP/IP network stack – a lack of evolvability. For most technologies, there is a steady cycle of innovation, adoption and deprecation. Remember DOS, OS/2, Windows 3.1, Windows 95? Right, that’s what they are: once ubiquitous, now mostly memories. In contrast, “Next Generation Internet” designs are mostly “Current Generation Internet +”. Plus AI and machine learning, plus digital ledger/blockchain, plus big data, plus augmented/virtual reality, plust platform as a service, plus ubiquitous surveillance. At the physical layer, there’s the push for higher bandwidth, both in the wireless and wired domains (optics and electronics) and at planetary (satellite links) and microscopic (nanonetworks) scales. A lot of innovation at the top and the bottom of the 7-layer model, but almost none in the core “networking” layers.
The prime example for the low evolvability of the ‘net is of course the adoption of IPv6, which is now slogging into its third decade. Now, if you think IPv6 adoption is taking long, contemplate how long it would take to deprecate IPv4. The reason for this is not hard to find. There is no separation between mechanism and policy – no service interface – at Layer 33. Craft a packet from the application and send it along. A lot of applications manipulate IP addresses and TCP or UDP ports all over their code and configurations. The difficulties in deploying IPv6 have been taken as a rationale that replacing core network protocols is inherently hard, rather than the symptom of an obvious defect in the interfaces between the logical assembly blocks of the current Internet.
For application programmers, the network itself has so little abstraction that the problem is basically bypassed alltogether by implementing protocols on top of the 7-layer stack. Far more applications are now developed on top of HTTP’s connection model and its primitives (PUT/GET/POST, …) resulting in so-called RESTful APIs, than on top of TCP. This alleviates at least some of the burden of server-side port management as it can be left a frontend web server application (Apache/Nginx). It much easier to use a textual URI to reach an application than to assign and manage TCP ports on public interfaces and having to disseminate them accross the network4. Especially in a microservice architecture where hundreds of small, tailored daemons, often distributed across many machines that themselves have interfaces in different IP subnets and different VLANs, working together to provide a scalable and reliable end-user service. Setting such a service up is one thing. When a reorganization in the datacenter happens, moving such a microservice deployment more often than not means redoing a lot of the network configuration.
Innovating on top of HTTP, instead of on top of TCP or UDP may be convenient for the application developer, it is not the be-all and end-all solution. HTTP1/2 is TCP-based, and thus far from optimal for voice communications and other realtime applications such as aumented/virtual reality, now branded the metaverse.
The additional complexities in developing applications that directly interface with network protocols, compared to the simplicity offered by developing on top of HTTP primitives may drive developers away from even attempting it, choosing the ‘easy route’ and further reduce true innovation in networking protocols. Out of sight, out of mind. Since the money goes where the (perceived) value is, and it’s hard to deprecate anything, the protocol real-estate between IP and HTTP that is not on the direct IP/TCP/HTTP (or IP/UDP/HTTP3) path may fall into further disarray.
We have experienced something similar when testing Ouroboros using our IEEE 802.2 LLC adaptation layer (the ipcpd-eth-llc). IEEE 802.2 is not used that often anymore, most 802.2 LLC traffic that we spotted on our networks were network printers, and the wireless routers were forwarding 802.2 packets with all kinds of weird defects. Out of sight, out of mind. This brings us nicely to the next problem.
Protocol ossification
Let’s kick this one off with an example. HTTP35 is designed on top of UDP. It could have run on top of IP. The reason why it’s not is mentioned in the original QUIC protocol documentation, RFC 9000: QUIC packets are carried in UDP datagrams to better facilitate deployment in existing systems and networks. What it’s basically saying is also what we have encountered evaluating new network prototypes (RINA and Ouroboros) directly over IP: putting an non-standard protocol number in an IP packet will cause any router along the way to just drop it. If even Google thinks it’s futile…
This is an example of what is referred to as protocol ossification. If a protocol is designed with a flexible structure, but that flexibility is never used in practice, some implementation is going to assume it is constant.
Instead of the IP “Protocol” field in routers that I used in the example above, the usual examples are middleboxes – hardware that perform all kinds of shenanigans on unsuspecting TCP/IP packets. The reason why these boxes can work is because of the violations of the two important design principles. The example from the wikipedia page, on how version negotiation in TLS1.3 was preventing it from getting deployed, is telling.
But it happens deeper down the network stack as well. When we were working on the IRATI prototype, we wanted to run RINA over Ethernet. The obvious thing to do is to use the ARP protocol. Its specification, RFC826, allows any protocol address (L3) to be mapped to a hardware address (L2). So we were going to map RINA names, with a capped length of max 256 bytes to adhere to ARP, to Ethernet addresses. But in the Linux kernel, ARP only supports IP. I can guarantee that with all the architectural defects in the TCP/IP stack, that “future” mentioned in the code comment will likely never come. Sander actually implemented an RFC826-compliant ARP Linux Kernel Module when working on IRATI. And we had to move it to a different Ethertype, because the Ethernet switches along the way were dropping the RFC-compliant packets as suspicious!
A message falling into deaf ears
So, why do we care so much about this, why so many in the network research community seem not to?
The (continuing) journey that is Ouroboros has its roots in EC-funded research into the Recursive Network Architecture (RINA)6. A couple of comments that we received at review meetings or some peer reviews from papers stuck with me. I won’t go into the details of who, what, where and when. All these reviewers were, and still are, top experts in their respective fields. But they do present a bit of a picture of what I think is the problem when communicating about core architectural concepts within the network community7.
One comment that popped up, many times actually, is “I’m no software engineer”. The research projects were very heavy on actual software development, so, since we had our interfaces actually implemented, it was only natural to us to present them from code. I’m the first to agree that implementation details do not matter. There surely is no point going over every line of code. But, as long as we stuck to component diagrams and how they interact, everything was fine. But when the interfaces came up, the actual primitives that detailed what information was exchanged between components, interest was gone. Those interfaces are what make the architecture shine. We spent literally months refining them. At one review, when we started detailing these software APIs, there was a direct proposal from one of the evaluation experts to “skip this work package and go directly to the prototype demonstrations”. I kid you not.
This exemplifies something that I’ve often felt. A bit of a disdain for anything that even remotely smells like implementation work by those involved in research and standardization. Becoming adept in the principles of separation and policy and separation of concern is a matter of honing ones’ skill, not accumulation of knowledge. If software developers break the principles it leads to spaghetti code. Breaking them at the level of standards leads to spaghetti standards. And there can’t be a clean implementation of a spaghetti standard.
The second comment I recall vividly is “I’m looking for the juicy bits”, and it’s derivatives “What can I take away from this project?“. A new architecture was not interesting unless we could demonstrate new capabilities. We were building a new house on a different set of foundations. The reviewers would happily take a look, but what they were really interested in, was knocking off the furniture. Our plan was really the same, but the other way around. Ouroboros (and RINA) aren’t about optimizations and new capabilities. At least not yet. The point of doing the new architecture is to get rid of the ossification, so that when future innovations arrive, they can easily be adopted.
Wrapping up
The core architecture of the Internet is not ‘done’. As long as the overwhelming consensus is that “It’s good enough” that is exactly what it will not be. A house built on an unstable foundation can’t be fixed by replacing the furniture. Plastering the walls might make it look more appealing, and fancy furniture might even make it feel temporarily like “home” again. But however shiny the new furniture, however comfortable the new queen-sized bed, at some point in time the once barely-noticeable rot seeping through the walls becomes ever more apparent, ever more annoying, ever harder to ignore, until the only remaining option is to move out.
When that realization comes, know that some of us have already started building on a different foundation.
As always, stay curious.
Dimitri
I use Internet in a restrictive sense, meaning the packet-switched TCP/IP network on top of the (optical) support backbones, not for the wider ecosystem on top of (and including) the world-wide-web.
[return]How do IPv4 packets reach the default IP gateway? A direct lookup by L3 into the L2 ARP table! And why would IPv6 even consider including the MAC address in the IP address if these layers were independent?
[return]Having an API is of course no guarantee to fast paced innovation or revolutionary breakthroughs. The slowing innovation into Operating Systems Architecture is partly because of the appeal of compatibility with current standards. Rather than rethinking the primitives for interacting with the OS and providing an adaptation layer for backwards compatibility, performance concerns more often than not nip such approaches in the bud before they are even attempted. Optimization really is the root of all evil. But at least, within the primitives specified by POSIX, monokernels, unikernels, microkernels are still being researched and developed. An API is better than no API.
[return]As an example, you reach the microservice on “https://serverurl/service" instead of on “https://serverurl:7639/". This can then redirect to the service on the localhost/loopback interface on the (virtual) machine, and the (TCP) port assigned to the service only needs to be known on that local (virtual) machine. In this way, a single machine can run many microservice components and only expose the HTTPS/HTTP3 port (tcp/udp 443) on external interfaces.
[return]HTTP3 is really interesting from an architectural perspective as it optimizes between application layer requests and the network transport protocol. The key problem – called head of line blocking – in HTTP2 is, very roughly, this: HTTP2 allows parallel HTTP requests over a single TCP connection to the server. For instance, when requesting an HTML page with many photographs, request all the photographs at the same time and receive them in parallel. But TCP is a single byte stream, it does not know about these parallel requests. If there is packet lost, TCP will wait for the re-transmissions, potentially blocking all the other requests for the other images even if they were not affected by the lost packets. Creating multiple connections for each request also has big overhead. QUIC, on the other hand integrates things so that the requests are also handled in parallel in the re-transmission logic. Interestingly, this maps well onto Ouroboros’ architecture which has a distinction between flows and the FRCP connections that do the bookkeeping for re-transmission. To do something like HTTP3 would mean allowing parallel FRCP connections within a flow, something we always envisioned and will definitely implement at some point, and mapping parallel application requests on these FRCP connections. How to do HTTP3/QUIC within Ouroboros’ flows + parallel FRCP could make a nice PhD topic for someone. But I digress, and I was already digressing.
[return]- This is the story all about how. [return]
These are a few examples are to highlight what I think is a core difference in priorities between what we tried to achieve with the projects – a flexible architecture in the long term – versus what most current research and development is targeted at – fixes for urgent problems and improvements in the short term. I want to stress that we were never treated unfairly by any reviewer, and this section should not be read as a complaint of any sort.
[return]