Loc/Id split and the Ouroboros network model
A few weeks back I had a drink with Thijs who is now doing a master’s thesis on Loc/Id split, so we dug into the concepts behind Locators and Identifiers and see if matches or in any way interferes with the Ouroboros network model.
For this, we started from the paper Locator/Identifier Split Networking: A Promising Future Internet Architecture1.
Loc/Id split?
In a nutshell, Loc/Id split starts from the observation that the transport layer (TCP, UDP) is tightly coupled to network (IP) addresses via a certain TCP/UDP port.
Assuming our IPv4 local address is 10.10.0.1 /24 and there is an SSH server on 10.10.5.253 /24 listening on port 22, after making a connection, our client application could be bound to 10.10.0.1 /24 on port 25406. If we move our laptop to another room that is on an access point in a different subnet, and we receive IP address 10.10.4.7 /24, our TCP connection to the SSL server will break.
Loc/Id split suggest to split the “address” into two parts, an Identifier that is location-independent and specifies the who at the transport layer, and a locator that is location-dependent and specifies the where at the network layer. Since an IPv6 address has more than enough (128) bits, there’s plenty of space to chop it up and attach some semantics to the individual pieces.
Of course, after the split, identifiers need to be mapped to locators, so there is a mapping system needed to resolve the locator given the identifier. This mapping system resides in a Sub-Layer between the transport layer and the network layer. If this mapping system sounds a lot like DNS to you, then you’re right, but then remember that TCP doesn’t bind to a DNS name + port, but to an IP address + port. That’s where the issue lies that the Identifier tries to solve.
Resolving the Locator from the Identifier usually happens in the end-host, but some Loc/Id split proposals may forward this responsibility to other nodes in the network. When only end-hosts perfom Id->Loc resolution, it’s called a host-based Loc/Id split architecture, if some other nodes perform Id->Loc resolution it’s called a network-based architecture. In a network-based architecture, the identifier MUST be part of the packet header (in a host-based architecture it’s optional), and the network nodes forward towards a resolver node based on the identifier and then when the locator is known based on the locator towards the end-host. I have my doubts that this can ever scale, so in this article, I’ll focus on host based Loc/Id split. Host-based architectures are summarized in the figure below, taken from the survey paper1.
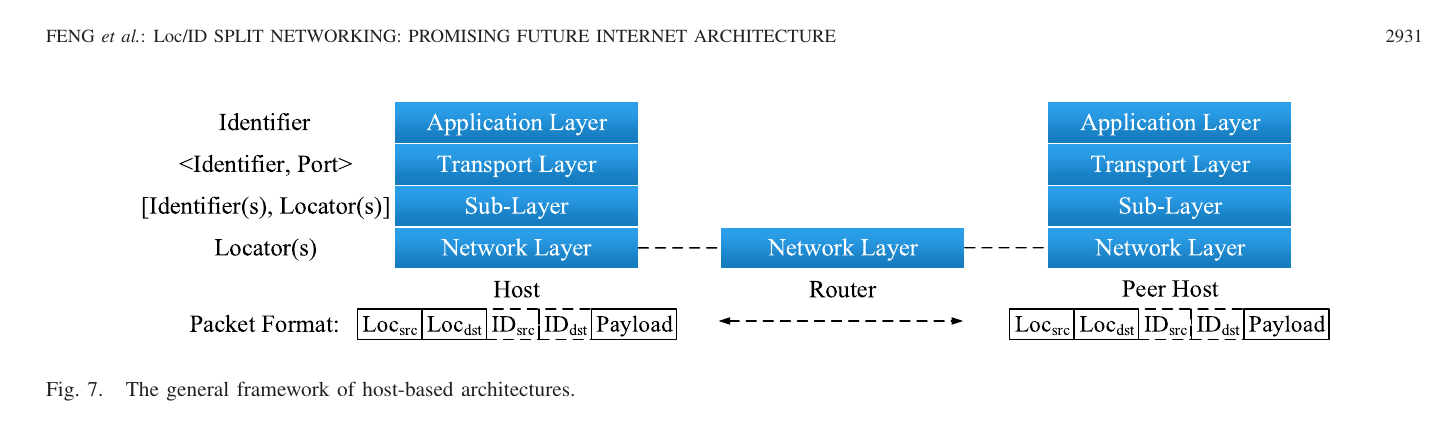
My first reaction to seeing that was sounds about right to me, it’s almost identical to what O7s proposes for a fully scalable and evolvable architecture. But before I get to that, let’s first dig a bit deeper into those locators and identifiers. What are these beasts?
Mobility in Loc/Id split
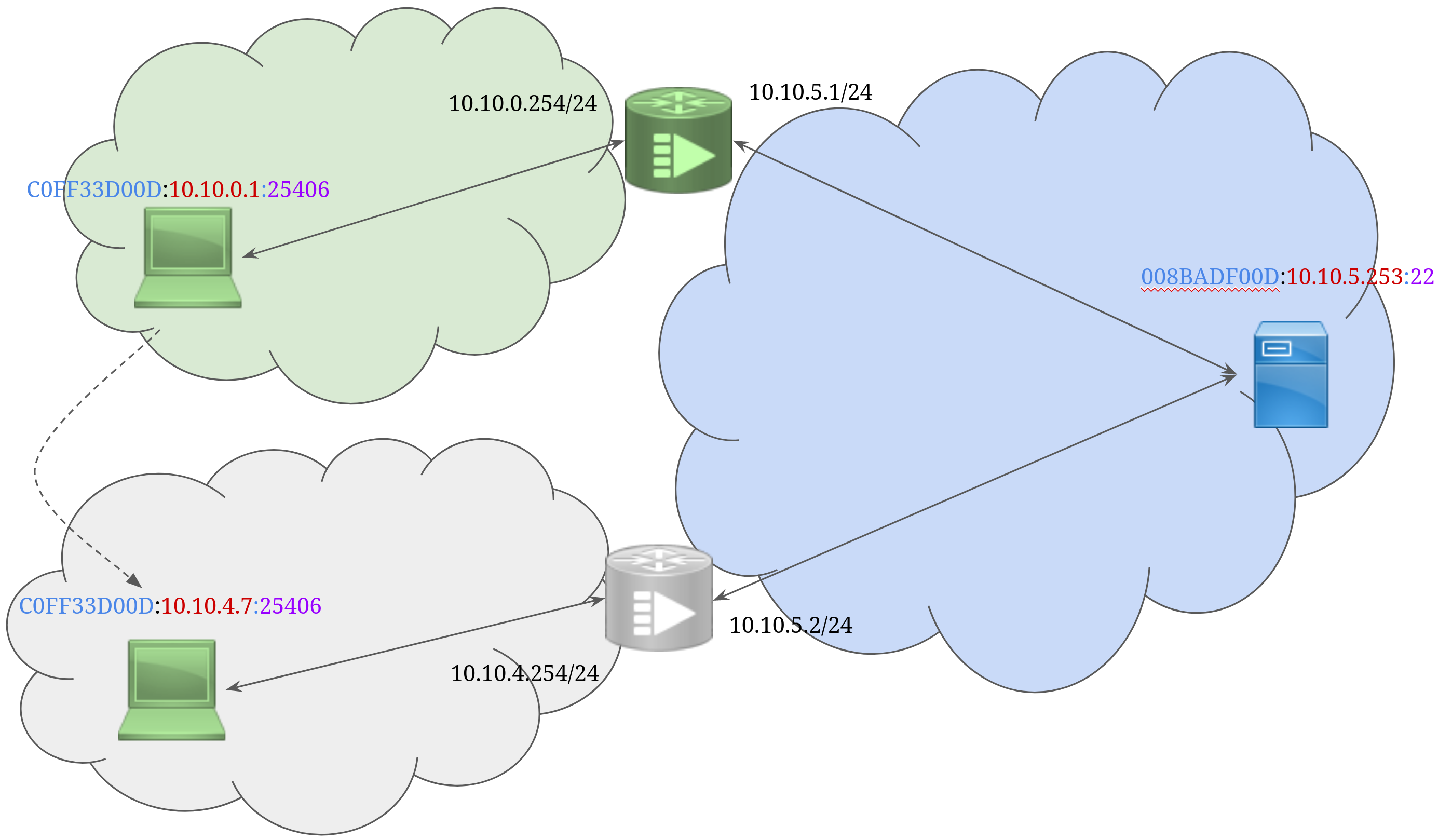
Let’s assume the previous example where, from my laptop, I’m connected to some SSH server, but this time we’re in a Loc/Id split network. So my laptop got a different address for its interface, an identifier, say COFF33D00D, and, since I’m in the green network, a locator that is conveniently the IPv4 address for my wireless LAN interface, 10.10.0.1 /24. The TCP connection in the SSH client is Loc/Id aware, and now bound to C0FF33D00D:25406. After connecting to the client at 008BADF00D, It learns that I’m C0FF33D00D and my locator is 10.10.0.1.
When I move to another floor, the laptop WLAN interface gets a new locator, but my identifier stays the same. It’s now C0FF33D00D:10.10.4.7. The OS is implementing a host-based Loc/Id split architecture, so I quickly send a loc/id update message to the server at 10.10.5.253 that my locator for C0FF33D00D has changed to 10.10.4.7, and it updates its mapping. The Loc/Id-aware TCP state machine in my laptop had some packet loss to deal with while I was in the elevator, but other than that, since it was bound to my identifier the connection remains intact.
Nice! Splitting an address into a locator and identifier has a pretty elegant solution to mobility.
Notice I didn’t give the routers identifiers parts in their address? That’s on purpose.
Let’s take a little thought experiment.
Instead of moving to the other floor, I already have a laptop already sitting there. Its WLAN interface has address COFFEEBABE:10.10.4.7.
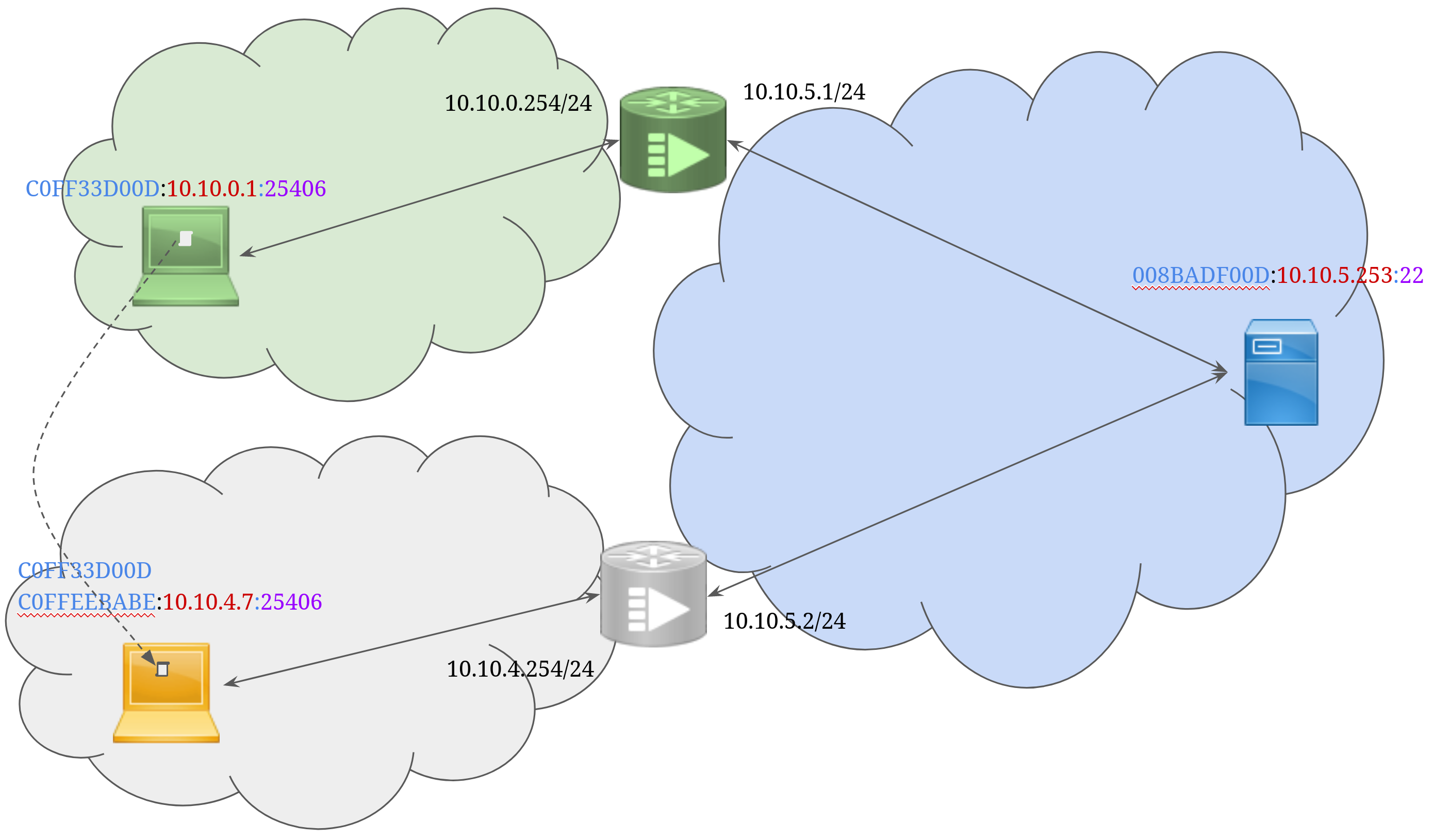
Now, what I do in this thought experiment, is copy the entire program state of my SSH client to that other laptop, including the TCP state2 and fork it as a new process on the other laptop. What is needed to make it work from a network perspective?
Well, like when actually moving with my laptop, I need to update the server that my identifier C0FF33D00D has moved to another locator at 10.10.4.7. That should do the trick, quite easy.
Unless there was already another application connected on port 25406 on that destination laptop. Then there is no way for the incoming laptop to know where to deliver the packets to. Unless the identifier is in the packet header. But host-based Loc/Id split had them optional? This seems to hint that host-based Loc/Id split supports device mobility but cannot fully support application mobility3.
So, what is that identifier actually naming? Well, all that moved was the application state, and the identifier seemed to move with it… And since the routers in the example don’t run “end-host” applications, they don’t need identifiers.
What does the Ouroboros model say?
Ouroboros4 gives each application process a name, which is mapped to an IPCP’s address5. The O7s application name basically corresponds to the identifier, and the IPCPs address maps to the locator.
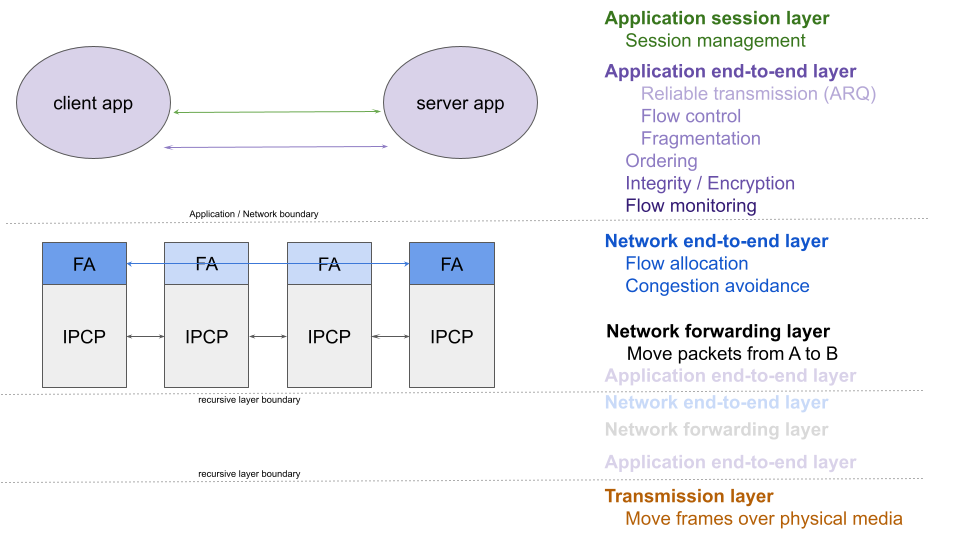
Let’s compare the architecture of Ouroboros above with the figure at the top.
First, the similarities. The Ouroboros model conjectures a split of the transport layer into an application end-to-end layer (roughly TCP without congestion avoidance) and a network end-to-end layer that includes the flow allocator.
The flow allocator in O7s performs the name <–> address mapping that is similar to id <–> loc mapping. Interesting to note is that in O7s, the Flow allocator is present in every IPCP, which is needed for Congestion Notifications. Given that identifiers are mapping to application names, resolving in name <–> address in other nodes than the source, like in network-based Loc/Id split, is not violating the O7s architecture. But we haven’t considered this as it doesn’t look feasible from a scalability perspective.
Now, the differences. First, the naming. The “identifier” in Ouroboros is a network/globally unique application name6. Processes7 can be bound to an application name. If a single process binds to an application name it’s unicast, if multiple processes on the same server bind to the same name, it provides per-connection load-balancing between these processes. If multiple processes on different servers bind to the same name, it provides a form of anycast name-based load-balancing.
Second, Ouroboros endpoint identifiers (EIDs) are only known to the Flow Allocator at the endpoint and specify the application. The O7s EID can be viewed as a combination of the L3 protocol field and the L4 port field into a single field that sits in between L3 and L4 (the Loc/Id proposed sublayer). This allows O7s to allocate a new flow (assigning new EIDs) while keeping the connection state in the process (FRCP) intact, and thus allowing full application mobility in addition to device mobility. Taking another look at the Loc/Id split figure, note that Ouroboros splits “network” from “application” just above the “Sub-layer”, instead of above the “transport layer”.
Wrapping up
The discussions on Loc/Id split were quite interesting. A lot of the steps and solutions it proposes are in line with the O7s model. What strikes me most is that LoC/Id split is still not very well-defined as a model. What exactly are identifiers? What exactly are locators? The thing that sets O7s apart is that the model consists of a limited amount of objects (forwarding elements and flooding elements, which form Layers8, application, process, …) that have well-defined names9 that are immutable and exist only for as long as the object exists.
- https://doi.org/10.1109/COMST.2017.2728478 [return]
This is hard to do with TCP state being in the kernel, but let’s forget about that and memory addresses and others stuff for a moment and assume the complete application state is a nice containerized package.
[return]The Ouroboros model does allow complete application mobility. The problem in this Loc/Id proposal is that the port is still part of the Transport Layer state (see the figure at the start of the post).
[return]This, and a lot of other things in O7s, were proposed in the RINA architecture, that’s where the credit should go.
[return]- To be accurate: we hash the application name. [return]
At least, for a public Internetwork, they should be globally unique.
[return]In O7s, processes are named with a process name (which in the implementation maps to the linux process id (pid). Process names are only local (system) scope.
[return]I capitalize Layers, as these Layers that are made up of forwarding elements (unicast Layers) or flooding elements (broadcast Layers) have a different meaning than the layers in the discussion above. Maybe we should call them strata instead of Layers…
[return]Synonyms are allowed, but they serve no function in the architecture. As an example, application names are hashed (a synonym) which has practical implications for security and implementation simplicity, but the architecture is theoretically identical without that hash.
[return]