Application-level flow liveness monitoring
This week I completed the (probably final) implementation of flow liveness monitoring, but now in the application. In the next prototype version (0.19) Ouroboros will allow setting a keepalive timeout on flows. If there is no other traffic to send, either side will send periodic keepalive packets to keep the flow alive. If no activity has been observed for the keepalive time, the peer will be considered down, and IPC calls (flow_read / flow_write) will fail with -EFLOWPEER. This does not remove any flow state in the system, it only notifies each side that the peer is unresponsive (presumed dead, either it crashed, or deallocated the flow). It’s up to the application how to respond to this event.
The duration can be set using the timeout value on the QoS specification. It is specified in milliseconds, currently as a 32-bit unsigned integer. This allows timeouts up to about 50 days. Each side will send a keepalive packet at 1⁄4 of the specified period (not configurable yet, but this may be useful at some point). To disable keepalive, set the timeout to 0. I’ve set the current default value to 2 minutes, but I’m open to other suggestions.
The modified oecho application looks as follows (decluttered). On the server side, we have:
while (true) {
fd = flow_accept(NULL, NULL);
printf("New flow.\n");
count = flow_read(fd, &buf, BUF_SIZE);
printf("Message from client is %.*s.\n", (int) count, buf);
flow_write(fd, buf, count);
flow_dealloc(fd);
}
return 0;And on the client side, the following example sets a keepalive of 4 seconds:
char * message = "Client says hi!";
qosspec_t qs = qos_raw;
qs.timeout = 4000;
fd = flow_alloc("oecho", &qs, NULL);
flow_write(fd, message, strlen(message) + 1);
count = flow_read(fd, buf, BUF_SIZE);
printf("Server replied with %.*s\n", (int) count, buf);
/* The server has deallocated the flow, this read should fail. */
count = flow_read(fd, buf, BUF_SIZE);
if (count < 0) {
printf("Failed to read packet: %zd.\n", count);
flow_dealloc(fd);
return -1;
}
flow_dealloc(fd);Running the client against the server will result in (1006 indicates EFLOWPEER).
[dstaesse@heteropoda website]$ oecho
Server replied with Client says hi!
Failed to read packet: -1006.
How does it work?
In the first post on this topic, I explained my reasoning how Ouroboros should deal with half-closed flows (flow deallocation from one side should eventually result in a terminated flow at the other side). The implementation should work with any kind of flow, which means we can’t put in the the FRCP protocol. And thus, I argued, it had to be below the application, in the flow allocator. This is also where we implemented it in RINA a few years back, so it was easy to think this would directly translate to O7s. I was convinced it was right.
I was wrong.
After the initial implementation, I noticed that I needed to leak the FRCP timeout (remaining Delta-t) into the IPCP. I was not planning on doing that, as it’s a layer violation. In RINA that is not as obvious, as DTCP is already in the IPCP. But in O7s, the deallocation first waits for Delta-t to expire in the application1 before telling the IPCP to get rid of the flow (where it’s an instantaneous operation). This means that for flows with retransmission, the keepalive timeout will first wait for the peers’ Delta-t timer to expire (because the flow isn’t deallocated in the peer’s IPCP until it does), and then again wait for the keepalive to expire in it’s own IPCP. With 2 minutes each, that means the application would only timeout after 4 minutes after the deallocation. To solve that with keepalive in the flow allocator, I would need to pass the timeout to the flow allocator, and on dealloc tell it to stop sending keepalives, and wait for the longest of the [keepalive, delta-t] to expire before getting rid of the flow state. It would work, it wouldn’t even be a huge mess to most eyes. But it bugged me tremendously. It had to be in the application, as shown in the figure below.
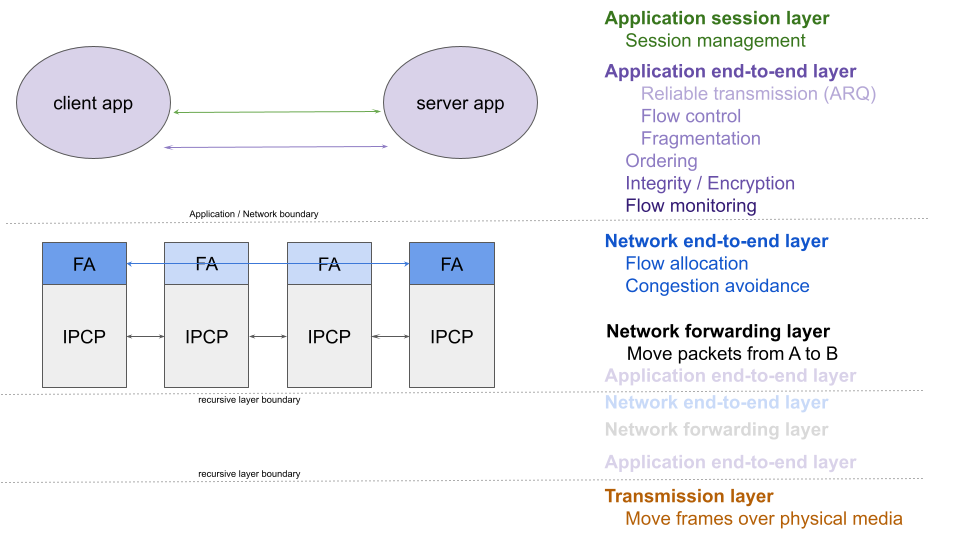
But this poses a different problem: how to spot keepalive packets from regular traffic. As I said many times before, it can’t be in FRCP, as it wouldn’t work with raw flows. It also has to work with encryption. Raw flows have no header, so I can’t mark them easily, and adding a header just for marking keepalive flows is also a bridge too far.
I think I found an elegant solution. 0-length packets. No header. No flags. Nothing. Nada. The flow at the receiver gets notified of a packet with a length of 0 bytes from the flow, updates it last activity time, and drops the packet without waking up application reads. Works with any type of traffic on the flow. 0-byte reads on the receiver already have a semantic of a partial read that was completed with exactly the buffer size2. The sender can send 0-length packets, but the effect will be that it is a purposeful keepalive initiated at the sender.
Logically in the application. After all packets are acknowledged, the application will exit and the IRMd will just wait for the remaining timeout before telling the IPCP to deallocate the flow. This is also a leak of the timeout from the application to the IRMd, but it’s an optimization that is really needed. Nobody wants to wait 4 minutes for an application to terminate after hitting Ctrl-C. This isn’t really a clear-cut “layer violation” as the IRMd should be considered part of the Operating System. It’s similar to TCP connections being in TIME_WAIT in the kernel for 2 MSL.
[return]If flow_read(fd, buf, 128) returns 128, it should be called again. If it returns 0, it means that the message was 128 bytes long, if it returns another value, it is still part of the previous message.
[return]